Add some Spark-le to your life.
Hey folks, I know I have been under the radar for a really long time. Its because I have attempted a lot of different projects throughout 2018 and the later half of 2017. Some of the projects have not had the desired level of success. However there is no such thing as failure there are only lessons waiting to be learned.
With that being said this was a project I had done in the later half of 2017. The idea was given to me by a former colleague. The goal was to scrape data from a bar’s website which shared the amount of a given brand remaining at any given time. After I have collected this data I wanted to perform some time series analysis using the ARIMA model and execute it on an Apache Spark cluster. Rough architecture diagram is attached below.
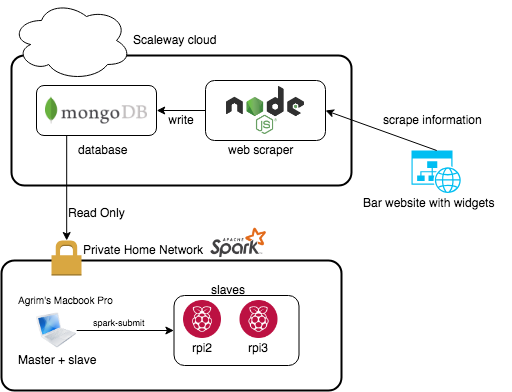
So the website I was trying to scrape had a widget that shows a small barrel which would change color / height of filling depending upon how much beer of that particular brand was left behind. I needed to parse some CSS so I found cheerio.js to be helpful in ingesting html and rendering the required elements correctly. Once that was done using some simple mathematics I was able to compute the percentage remaining. Attached the censored source code for the scraper below
I ran the above for about 2 weeks on one of my VPS’s. Once I had enough data I went ahead and began implementing the ARIMA model code which I got from here.
So initially it was taking forever to run the model on two raspberry pi’s plus my macbook, So I decided to add some more resources and scale up my solution. Using the brilliant scaleway cli I spun up 2 VC1M instances and added them as slaves in my deployment. That changed my architecture as follows.
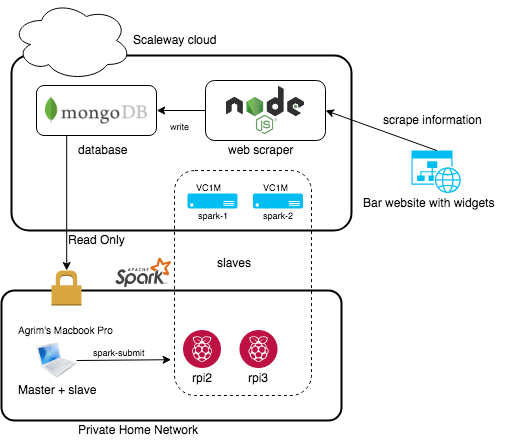
The great thing about the scaleway cli is that its commands resemble the docker cli ,which is in muscle memory for me. I could spin up/down vms on the fly just like I would do with docker containers. This made the project a lot more affordable as I could spin up the compute nodes only when I want to run the model. I had to do a small hack by running a local tunnel on my macbook so that the vms could call into my laptop. So now that all the sunshine and rainbows part is over lets get to the actual scrutiny of the project.
So why did this project fail ?
- Data was very inconsistent.
- CSS rendering was inaccurate leading to bad measurements.
- Not enough samples were collected.
- Database was not ideal for time-series data analysis
What were the key learnings of this experiment?
- Apache Spark is an amazing distributed computing engine that can be setup easily and runs across different architectures ARM,x86 etc due to the portable nature of the JVM.
- Data is the new gold, without good data you cannot do any kind of useful analysis.
- We are living in an awesome timeline where we can request resources dynamically and pay only for what we use.
- Always do some basic groundwork like a technical evaluation before starting any project.
Thats all for this blog post stay tuned for more exciting and successful projects coming up!
Disclaimer: I have tried not to mention any brands/locations or url’s for privacy reasons. Also contributions are welcome!
https://github.com/agrimrules/brewery


